|
|
|
|
|
|
Русские названия шахматных фигур. Часть 3.
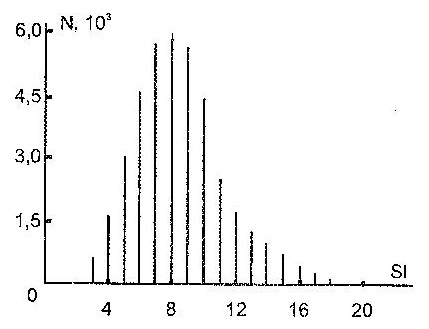
Частотные свойства поля существительных Частотная модель структурной неординарности звуковой формы слова разработана В. Н. Беловым с учетом статистических свойств поля существительных. Исследовалась выборка существительных, составленная на основе академического орфографического словаря русского языка (см. 21), включающего в себя современную лексику, что позволило выполнить анализ в широком понятийном диапазоне безотносительно к особенностям профессиональной терминологии, в основном, не присутствующим в словарном материале. Выбранные 43535 непроизводных слов, принадлежащие полю существительных, содержали 378239 звукобукв. Принципиально важен следующий аспект анализа. Фактически исследовались линейные цепочки звукобукв, отражающие лишь их наличие в звуковой форме слова. Вместе с тем, это не совсем слова, так на данном этапе анализа не учитывалась психологическая составляющая восприятия звуковых форм, которая выделяет первые и ударные звукобуквы, наделяя их большей значимостью в произнесенном и услышанном слове. Поэтому исследовались, скорее, «зародыши», в большей степени отражающие звукобуквенный состав слов. Психолингвистический аспект учтен при построении частотной модели структурной неординарности слова. Зарегистрированное распределение слов по звукобуквенным длинам приведено на рис. 2. Подходя к свойствам распределения как к проявлению комбинаторно-логической звукобуквенной структуры языка, свойства распределения с большой мерой обоснованности можно проецировать на механизм словообразования в языке, чтобы выявить его фонетический механизм. Внимания заслуживает следующий факт. Количество слов убывает при увеличении или уменьшении их звукобуквенной длины. Это свидетельствует о недостаточности или избыточности их фонетического образа, регулирующего длительность существования слов в языковой среде, а значит, норма находится где-то посередине. Языковая практика задает границы нормы, но не накладывает абсолютного запрета на отклонения. Указанный механизм имеет прямое отношение к саморегуляции языка – ограничению тенденции произвольности в нем. Проведенный ниже анализ средней частотной информативности слов разной длины показывает, что уменьшение количества слов приходится на малые и большие значения частотной информативности: языковая среда, по возможности, избегает крайностей.
Рис. 2. Вид гистограммы распределения слов по звукобуквенным длинам. После проведения статистического анализа распределения количества слов по их длине среднее <Sl> и несмещенное среднеквадратичное отклонение s, задающее оценку дисперсии z , оказались равными <Sl> = 8,69 и z @ s 2 = 8,80. Исходя из этого, с высокой степенью точности можно считать установленным факт пуассоновой природы полученного распределения. Из известных только распределение Пуассона характеризуется связью среднего и дисперсии z2 = <Sl>, полученной экспериментально. Совпадение среднего и дисперсии с точностью до 1% делает ненужным дальнейшую идентификацию типа полученного распределения, то есть вычисление и анализ его более высоких моментов. Рассчитанное по Пуассону количество слов для Sl = 1 (одной звукобуквы) составляет 64, что соответствует количеству анализируемых звукобукв равному 46. Однако в настоящей работе звукобуквы рассматривались не как слова, а как бесструктурные производящие единицы языка. Рассмотрим этот аспект фонетического пространства русского языка более подробно. Считая установленным пуассонов характер существующего в языке распределения слов по их звукобуквенным длинам, можно сделать важнейшее заключение о роли звукобукв в процессе формирования слов. Статистически распределение Пуассона возникает в результате сложения большого количества событий, характеризуемых равной вероятностью. В рассматриваемой ситуации природа распределения Пуассона имеет отношение к формированию слова и означает, что все звукобуквы в слове обладают равной вероятностью быть использованными при его появлении. Следовательно, для процесса словообразования звукобуквы (с учетом их частотностей) представляют собой бесструктурные производящие единицы языка. Их случайные комбинации, закрепленные в речевой практике, создают словарное наполнение языка. Данный факт является краеугольным при построении частотной модели. Степень участия конкретной звукобуквы в случайных комбинаторных продуктах, то есть словах, будет учтена через ее частотность, определяющую психолингвистический фактор, имеющий, как следует из рассмотрения, чисто частотное наполнение. Со статистической точки зрения, при обобщении по времени, пространству и носителям языка, появление слова предстает как случайный процесс, в котором речевая практика заимствует единицы языка из океана звукобукв, в котором звукобуквы случайным образом перемешаны, что не создает преимущества ни одной из них. Соотношение частотностей звукобукв - единственное, что определяет структуру такого аллегорического океана. В этом смысле его можно сравнить с океаном обычным, в котором естественные процессы поддерживают химический состав морской воды, являющейся смесью. Аллегория передает статистический аспект словотворчества, для которого все звукобуквы фонетически, но не количественно (в смысле их распространенности в речевой практике), равноправны. Пока что обсуждалось формирование слов-«зародышей» на этапе их первоначального появления в языке. Однако речевая практика вносит в полученный лексический материал свои коррективы. Из языка уходят артикуляционно сложные и неблагозвучные сочетания звуков, равным образом затрагивая все слова-«зародыши». В результате коррекции происходит приближение к языковой норме, той лексике, которая составляет наполнение языка. Этот вторичный процесс с равной вероятностью затрагивает все линейные цепочки звукобукв, так как «неудобные» сочетания встречаются в них с равной вероятностью. А значит, первоначально возникшее распределение не оказывается искаженным, оно испытывает линейное преобразование масштаба по количеству слов, в результате чего остается только общепринятая лексика. При невыполнении указанного механизма редукции цепочек звукобукв к словам экспериментально зарегистрированное распределение слов по звукобуквенным длинам не представляло бы собой распределения Пуассона.
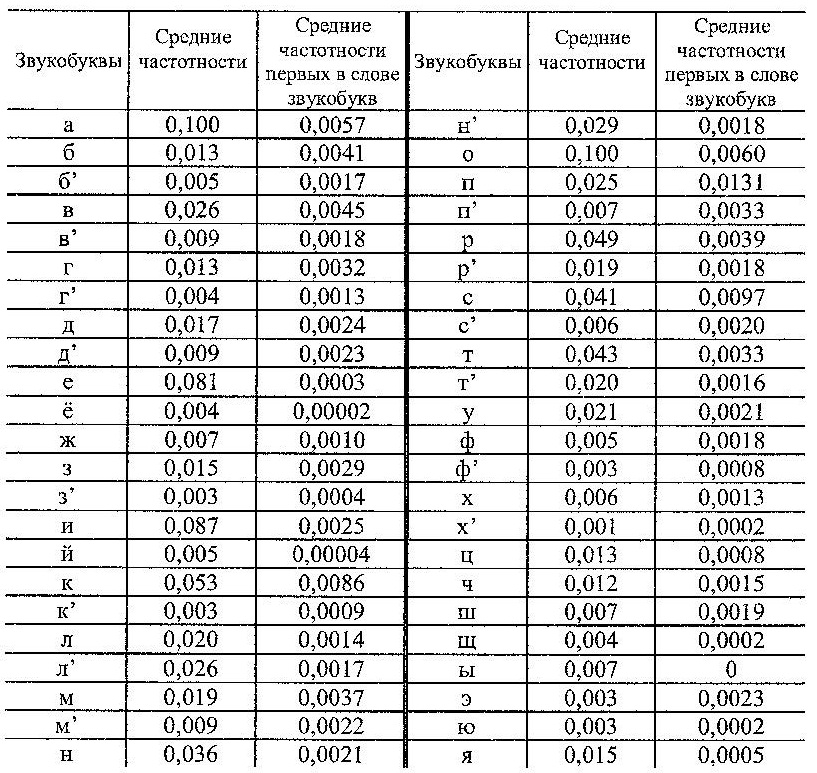
Средние частотности звукобукв. Средние частотности (без выделения ударных гласных) приведены в табл. 1. Суммарная средняя частотность гласных составляет 42,1%, согласных – 57,9%. Средние частотности представляют собой достаточно высокий уровень обобщения – экспериментально зафиксированы значительные вариации частотностей при изменении длины слов. Надо полагать, что в восприятии вместо набора вариантных численных значений каждой звукобукве сопоставляется некоторый усредненный частотный образ, построенный на опыте речевой практики носителя языка. Хотя индивидуальный опыт может варьироваться, он не может не отражать звукобуквенной структуры языка в целом. Табл. 1. Средние экспериментальные частотности звукобукв. Первые звукобуквы слов.
Частотности первых звукобукв слов (без выделения ударных гласных), которыми могут быть как согласные, так и гласные, приведены в третьем столбце табл. 1. Суммарная частотность первых звукобукв составляет 11,5% и соответствует обратной средней звукобуквенной длине слова (8,69 звукобукв), что понятно, так как на каждое слово приходится одна ударная гласная. Соотношение частотности первой в слове звукобуквы к ее средней частотности варьируется от 0 для «ы» до 167 для «ё», заполняя весь промежуточный интервал значений. Надо полагать, что защитой механизмов восприятия от перегрузки дополнительной информацией о вариациях частотности звукобуквы, определяемых её положением в слове, должен служить обобщенный образ звукобуквы. Предположение об ориентации восприятия первых звукобукв на норму получило экспериментальное обоснование. Им служит найденное значение коэффициента корреляции средних значений частотностей звукобукв и частотностей первых звукобукв (по данным табл. 1), которое составляет 0,43. Такое значение коэффициента характеризует связь сходства, которое способствует переносу усредненного образа звукобуквы на менее частотную первую. Этот вывод учтен при построении частотной модели.
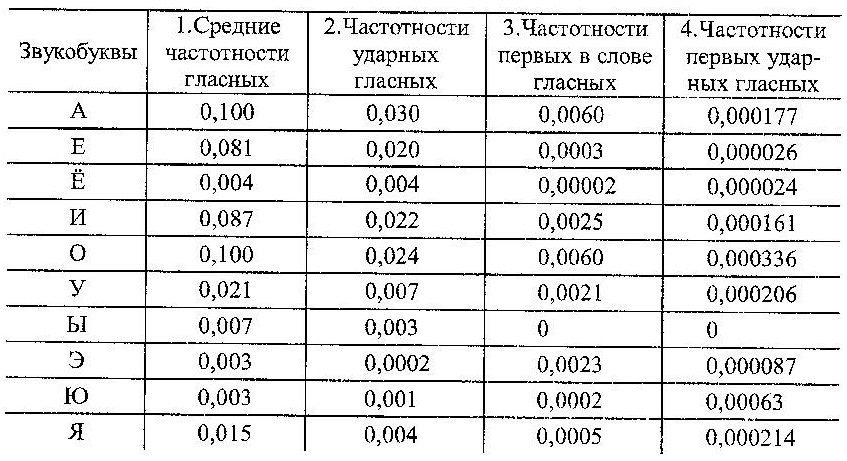
Табл. 2. Средние частотности гласных,ударных, первых и первых ударных гласных.
Ударные гласные. Разброс отношений средних частотностей гласных к частотностям ударных гласных также достаточно велик: от 1 для «ё» до 13 для «э». В табл. 3 приведены результаты вычисления коэффициентов взаимной корреляции средних частотностей гласных, ударных, первых и первых ударных гласных. Сами частотности помещены в табл. 2.Увеличение количества признаков, сопутствующих расположению и психологической роли гласной в слове, приводит к уменьшению сходства выделенного набора с набором средних частотностей гласных. Вместе с тем, существует очень высокая связь сходства частотностей ударных и средних частотностей гласных в слове, характеризуемая коэффициентом корреляции 0,99. Наименее всего связаны между собой признаки гласной быть ударной в слове (независимо от позиции) и первой ударной. Этот вопрос заслуживает особого внимания, так в частотной модели, согласно положениям психолингвистики, выделены первые, ударные и первые ударные звукобуквы слова. Полная частотность всех первых гласных слова составляет 0,0199 (табл. 2), то есть одна первая гласная приходится на 50 звукобукв, или в среднем на 6 слов. Полная частотность всех первых ударных гласных слова составляет 0,00130, другими словами, такая гласная встречается один раз среди 769 звукобукв, или среди 89 слов. Столь малая частотность вызывает веское сомнение в возможности её индивидуальной фиксации в речевой практике. Если гласные и согласные имеют в сумме близкие частотности и почти поровну встречаются в звукобуквенном составе слова, на их фоне дополнительные признаки, сопровождаемые малой долей вероятности, могут вообще не ощущаться. В этом случае субъективно воспринимаемая мера средней частотности может и, скорее всего, проецируется на другие признаки. Этот аспект восприятия учтен при построении частотной модели. |
ДлинасловаSl |
Средняяпозицияударной в слове |
Отношение среднейпозиции ударной к длине слова |
|
2 |
1,11 |
0,56 |
|
3 |
1,88 |
0,63 |
|
4 |
2,30 |
0,58 |
|
5 |
2,72 |
0,54 |
|
6 |
3,32 |
0,55 |
|
7 |
3,83 |
0,55 |
|
8 |
4,76 |
0,59 |
|
9 |
5,49 |
0,61 |
|
10 |
6,28 |
0,63 |
|
11 |
6,77 |
0,62 |
|
12 |
7,24 |
0,60 |
|
13 |
8,06 |
0,62 |
|
14 |
9,08 |
0,65 |
|
15 |
10,2 |
0,68 |
|
16 |
10,6 |
0,67 |
|
17 |
11,6 |
0,68 |
|
18 |
13,0 |
0,72 |
|
19 |
13,3 |
0,70 |
|
20 |
14,5 |
0,73 |
|
21 |
15,8 |
0,75 |
|
22 |
16,2 |
0,74 |
|
23 |
18,6 |
0,81 |
|
24 |
16,8 |
0,70 |
Частотная модель структурной неординарности
Равновзвешенность (бесструктурность) звукобукв. Структурная неординарность слова.
Как было указано выше, несмотря на фонетические различия слов поля существительных, состоящих из различных комбинаций звукобукв, на статистическом уровне образования линейной фонетической структуры они представляют бесструктурные цепочки звукобукв. Язык оперирует ими так же, как звукобуквами. Пуассонова статистика распределения слов по их звукобуквенным длинам фактически означает отсутствие в линейной комбинации звукобукв какой-либо значимой информации, так как длины слов сформированы по законам комбинаторики, производным от случайного стечения обстоятельств.
Но словотворчество нельзя признать совсем произвольным, то есть случайным. В языке одни звуки используются чаще и обладают большей частотностью, другие – меньшей. Учет этого осуществляет субъективно воспринимаемая носителями языка средняя частотность конкретной звукобуквы, которая задает относительное количество звукобукв, используемых в квазислучайном, как вернее, процессе словотворчества.
Все звукобуквы (с учетом их частотностей), вошедшие в состав фонетической цепочки, обладают равной вероятностью оказаться в слове на этапе его первоначального появления. Это означает, что они представляют собой бесструктурные (в плане словообразования) производящие единицы языка. Процесс фонетического конструирования нового слова предстает как квазислучайный процесс, в котором единицы языка заимствуются из однородного (с учетом частотности) перемешанного конгломерата звукобукв. Звукобуквы равноценны, а значит, тождественны в сознании человека, в силу тех или иных причин создающего новую фонетическую форму.
Различия между звуками, или практически соответствующими им в русском языке звукобуквами, на субъективном несимволическом уровне проявляются только в сложности или простоте артикуляции необходимой для их произнесения, что, впрочем, не ощущает усредненный носитель языка. Другое – комбинация звукобукв. В результате ее прочтения появляется полноценное слово, произнесенное и услышанное. Как только слово услышано, в сознании или вербально, самим создателем слова или его реципиентом, включается психолингвистический анализ звуковой формы с последующим отсевом артикуляционно сложных (в плане произнесения последовательности звукобукв) и неблагозвучных для восприятия носителя языка сочетаний звуков, который в одинаковой степени затрагивает все новообразованные слова, приводя их в соответствие с нормой. Определенную роль на этом этапе играют звукосимволизм и звукоподражание, увеличивая шансы на отсев для слов, не наделенных звукоизобразительностью по отношению к денотату. Следовательно, первоначально возникшее распределение по длинам слов не искажается, но линейные цепочки звукобукв в равной мере адаптируются к норме.
Изначальная тождественность звукобукв в плане структуры есть ни что иное как отсутствие структуры, бесструктурность, так как звукобуквы являются элементарными единицами языка. Тогда бесструктурными должны оказаться и случайно сформированные линейные комбинации звукобукв - с точки зрения теории вероятностей, содержательные упорядоченные структуры не возникают там, где царствует случай, а именно в случайной цепочке бесструктурных звукобукв, используемых для конструирования слова. «Зародыши» возможных слов в виде последовательности звукобукв, ввиду отсутствия связи смысла и формы те же «квазислова» в определении А. П. Журавлева (10 - с. 120), тождественно ординарны.
Это заключение никак не связано с содержанием процессов примарной или секундарной номинации объектов, состояний, явлений - рассматривается ли первичный процесс номинации с поиском подходящего «зародыша» звуковой формы для определенного признака денотата, или процесс вторичный, когда уже существующее в речевой практике слово приобретает новый смысл. Только что «выловленное» из океана звукобукв слово-«зародыш» бесструктурно, вне зависимости от того, из какого количества, каких звукобукв и их сочетаний оно состоит.
Слово-«зародыш» становится (или не становится) содержательным лишь тогда, когда оно прошло через фильтры восприятия. Внутренняя декламация или вербализация слова порождают переход от бесструктурности к субъективно воспринимаемой структуре или, если иметь ввиду речевую практику, порой произвольно варьирующую ударение, множеству структур. А поскольку есть структуры, появляется возможность количественно характеризовать их, то есть оценить субъективно воспринимаемые структурные фонентические отличия слов по отношению к их латентной фазе – цепочке звукобукв слова-«зародыша». В качестве соответствующей характеристики естественно использовать понятие «структурной неординарности».
При оценке структурной неординарности звуковых форм функционирующих в языке слов, фаза формирования которых завершилась, необходимо учитывать частотные характеристики звукобукв. Для этого предназначена построенная ниже частотная модель, которая статистически воспроизводит генерализованный психолингвистический механизм восприятия частотной составляющей звуковой формы слова.
Частотности звукобукв сложным образом зависят от звукобуквенной длины слов, что в принципе не позволяет носителю языка учесть множественность их нюансов, возникающих, в том числе, и по другим причинам. Однако, постоянно пользуясь языком, носитель приобретает обобщенную информацию о частоте использования звукобукв в речевой практике, в основном, ориентируясь на средние частотности. При этом в сознании формируется функциональный, то есть минимальный, образ звукобуквы, связанный с ее распространенностью. Этот образ проецируется реципиентом на фонетические аспекты слов при их восприятии, позволяя проводить сравнение на одном уровне обобщения. Частотная модель основана на воссоздании подобного рода последовательных и равной степени сложности обобщений (применительно к восприятию звуковых форм), связанных с переносом (проецированием) более общих признаков на частные их проявления.
Веса отдельных звукобукв.
Ввиду бесструктурности все звукобуквы (с учетом их частотностей) обладают тождественными комбинаторными свойствами при формировании слов-«зародышей». Это подводит к выводу об их равной структурной значимости в «зародыше», то есть равной структурной неординарности, которую без каких-либо дополнительных нормировок можно положить равной условной единице. Условной единицей должен тогда оцениваться и сам «зародыш» слова, поскольку все «зародыши» в силу своей случайной природы тождественны звукобуквам. Однако произнесенное слово уникально, при субъективном восприятии и оценивании его звуковой формы у реципиента доминирует аспект соотнесения звукобуквенного состава с нормой. Иначе и быть не может, так как сформировавшаяся языковая среда дана носителю языка с момента рождения, поэтому он подсознательно ориентируется на иерархию существующих форм.
Чем же отличаются звукобуквы в восприятии? Исключительно
связанной с ними частотностью, характеризующей их распространённость.
Психологическое воздействие звукобуквы тем сильнее, чем реже она присутствует в сложившейся речевой практике. Этот факт учтен в модели фонетического значения А. П. Журавлева (10 - с. 121–123), этот же факт обнаружен Ю. Н. Тыняновым (см. 26) при рассмотрении сочетаемости стихотворных рифмокомпонентов, установившим, что сила их взаимодействия (индуцируемый у читателя поэтический образ) оказывается обратно пропорциональной степени привычности (частоте) используемого автором соотнесения их в тексте. Сходным образом, пропорционально обратной частотности, формируются частотные образы звукобукв в линейной последовательности слова-«зародыша»: чем чаще звукобуква встречается в речевой практике, тем менее она значима в восприятии, тем менее ярким образом она наделена в сознании носителя языка.
А. П. Журавлев экспериментально установил указанный порядок сложения фонетических (фоносемантических) значений (значимостей) звукобукв при восприятии слова, который без каких-либо изменений может быть использован для сложения других характеристик звукобукв. В случае слова-«зародыша» происходит сложение характеристик структурной неординарности звукобукв условно равных «1» для получения характеристики структурной неординарности «зародыша», также равной «1». Применительно к слову-«зародышу» в формулу А. П. Журавлева вместо признаковых фоносемантических значимостей звукобукв необходимо подставить характеристики их структурной неординарности и учесть отсутствие дополнительных психологических весов, что дает:
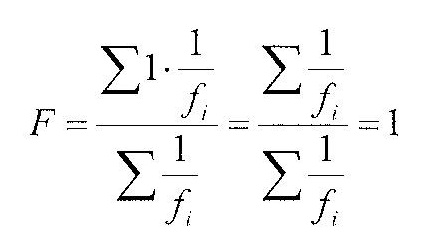
то есть воспроизводит ожидаемый результат (fi - частотность i - ой звукобуквы). Чтобы не употреблять каждый раз сочетание «характеристика структурной неординарности» слова удобно ввести новое понятие, а именно «частотная информативность» слова. Обозначив частотную информативность буквой F, (или в некоторых местах текста буквой f) приведенную выше формулу можно интерпретировать, как формулу вычисления значения частотной информативности слова-«зародыша».
Здесь необходимо пояснить важнейший аспект вычисления частотной информативности, который имеет смысл универсалии русского языка. Для любых слов-«зародышей», лишенных дополнительных психологических (статистических, как показано ниже) весов звукобукв, справедливо равенство:

вычисление частотной информативности дает слову универсальную характеристику, то есть абсолютно единообразно описывает любые слова.
Поскольку формула для расчета частотной информативности F функционирующего слова, востребованного речевой практикой, имеет знаменитель вида
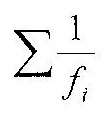 ,
,
то к этому знаменателю можно относиться как к ненормированной характеристике структурной неординарности слова-«зародыша», с которой соотносится характеристика функционирующего слова, стоящая в числителе. Результат деления дает абсолютное превышение неординарности слова (его структурную неординарность) по отношению к любому ординарному (бессструктурному) слову-«зародышу», состоящему из линейной последовательности неразличимых звукобукв.
Дополнительные веса.
Механизмы восприятия наделяют первую и ударную дополнительными весами, что приводит к разрушению бесструктурности линейной цепочки звукобукв слова. Аспект психологической значимости в восприятии звуковой формы обоснован А. П. Журавлевым (10 - с. 121-123). Но возможна другая трактовка. Звукобуква слова имеет меньшую вероятность оказаться первой или ударной, эти признаки менее частотны в слове, что придает первой и ударной дополнительные статистические веса: чем меньше частотность – тем выше вес по отношению к другим звукобуквам, не наделенным данным признаком. Используя свойственный восприятию прямой перенос усредненных признаков на выделенные, можно заключить: чем меньше вероятность обнаружить конкретный признак звукобуквы внутри слова – тем выше статистический, а следовательно, психологический вес звукобуквы по отношению к звукобуквенной норме. Следовательно, дополнительные веса первой и ударной определены их частотностями, оцениваемыми носителями языка из сложившейся речевой практики по отношению к усредненным частотностям.
Первые. Для первых звукобукв искомым признаком является их местоположение. При средней длине слова 8,69 звукобукв для отдельно взятой звукобуквы вероятность оказаться на первом месте составляет 1:8,69 = 0,115, а значит, вес первой в обратное число раз больше, то есть 8,69. Коэффициент корреляции средних частотностей и частотностей первых в слове звукобукв был вычислен при анализе частотных свойств поля существительных и составляет 0,43. Наличие корреляции по типу сходства поддерживает перенос средних частотных характеристик звукобукв на первые.
Ударные. Ударными являются исключительно гласные, количество которых составляет 42,1% от всех звукобукв. Вероятность оказаться ударной в слове имеет ту же величину, что и у первой, но по отношению ко всем звукобуквам слова. Такого рода сравнение не адекватно, поскольку фонетически гласные отличаются от согласных, составляя отдельную подсистему. Следовательно, носитель языка может проводить сопоставимое сравнение только с гласными. По отношению к гласным вероятность возрастает и составляет 0,115:0,421 = 0,273. Значит, вес ударной в слове, находимый как обратная величина, равен 3,66. Коэффициент корреляции экспериментально найденных средних частотностей гласных и частотностей ударных гласных звукобукв имеет значение 0,99 и характеризует практически полную связь между ними. Столь сильное сходство не просто поддерживает, а определяет перенос средних частотных характеристик гласных на характеристики ударных гласных.
Первые ударные. Для первых ударных совпадение двух дополнительных признаков, то есть положения на первом месте в слове и наличия ударения, означает их совместную независимую реализацию с вероятностью 0,115×0,273 = 0,0314. Следовательно, вес первой ударной, как обратная величина, равен 31,8.
В исследованной выборке первых ударных звукобукв 0,13%, то есть из 378239 звукобукв выборки на их долю приходится 492 звукобуквы и столько же слов (всего в анализируемой выборке 43535 слов). Столь небольшое количество слов (на уровне 1,1%), начинающихся с первой ударной, определяет их малую частотность в речевой практике, что не позволяет носителю языка создать независимый обобщенный образ первой ударной. Такой образ может дать только проецирование более частотных признаков. Поддерживает ли фонетический строй языка перенос признаков? Ответ следует искать в связях признакового сходства. Коэффициент корреляции средних частотностей гласных с частотностями ударных, первых и первых ударных гласных составляет соответственно 0,99, 0,73, 0,50. Коэффициент корреляции средних частотностей первых гласных и первых ударных гласных равен 0,74, корреляция средних частотностей ударных гласных и первых ударных характеризуется коэффициентом 0,46.
Связи сходства, действительно, существуют и четко фиксируются, они должны быть отражены в сознании носителя языка. В частотной модели отражение указанного факта выполнено через проецирование на свойства первых и ударных более частотных, генерализованных, свойств звукобукв.
Сравнение найденных дополнительных весов с весами «4» и «2», использованными А. П. Журавлевым, показывает, что они в среднем в два раза возросли, но практически не изменили своего соотношения – вместо отношения 2,00 : 1 из построенной модели следует 2,37 : 1.
Переход к средним частотностям позволил уйти от существовавшей в модели А. П. Журавлева диспропорции между дополнительными весами первых и ударных звукобукв, возникшей из-за непоследовательного подхода к их оцениванию. А именно, вес «4» для первых был отнесен к средним частотностям звукобукв, вес «2» для ударных - к средним частотностям ударных, которые в сумме составляют 11,5% всех звукобукв слов, в то время как все гласные составляют только 42,1%. Взвешивание фоносемантических хактеристик звукобукв происходит по обратным частотностям, как следствие, вес первых оказался заниженным, а ударных – завышенным.
Частотная информативность.
Изложенные аргументы позволяют сконструировать выражение для расчета частотной информативности слова, характеризующей его структурную неординарность, в виде:
![]()
![]()

Преобразованная форма записи показывает, что F принимает значения большие единицы и имеет смысл превышения структурной неординарности слова над ординарным словом-«зародышем» с характеристикой 1. Надобность в какой бы то ни было дополнительной нормировке полученного выражения отпадает. Анализ выражений показывает, что увеличение длины слова в среднем приводит к уменьшению F, уменьшение – к росту F. Это же демонстрируют результаты прямых расчетов по выборке существительных, проиллюстрированные на рис. 3.
Построенное выражение вместо фоносемантических значимостей оперирует структурными весами звукобукв. Оно выполняет статистическое «взвешивание» звукобукв слова по этой характеристике. «Взвешивание» касается количественных характеристик отдельных звукобукв, стоящих перед слагаемыми
![]()
в числителе выражения. Как известно, в статистике существует процедура для вычисления общего среднего и его погрешности.

Рис. 3. Вид зависимости средней частотной информативности <F> от звукобуквенной длины слова Sl.
Взвешивание разноточных результатов, в которых погрешности распределены по Гауссу или Пуассону, производится согласно приведенному выражению (см.,например 23?):
Рис. 3. Вид зависимости средней частотной информативности <F> от звукобуквенной длины слова Sl.

Психолингвистическое взвешивание характеристик звукобукв при их восприятии связывает значимость звукобуквы с обратной дисперсией ее частотности. Дисперсии средних частотностей менее частотных зукобукв меньше, восприятие отдает им предпочтение, создавая образы большей выразительности. Более частотные звукобуквы образуют «фон», на котором функционируют значимые фонетические формы.
Норма поля существительных.
На рис. 4 показано распределение количества слов по частотной информативности (использована нормировка на 1 в максимуме).
Среднее распределения <F>, которое следует считать нормой поля существительных, составляет 2,69.

Если судить по соотношению среднего (2,69) и дисперсии (2,38), то распределение достаточно близко к распределению Пуассона, что отражает дискретную звукобуквенную природу анализируемого материала.
Естественная фоносемантическая шкала.
Ось частотных информативностей F на рис. 4 можно рассматривать как линейную шкалу, ранжирующую слова языка по этой характеристике. Поскольку расстановка объективна и задана звуковой формой слов, в силу звукоизобразительности русского языка шкалу необходимо атрибутировать как фоносемантическую. Экспериментальное обоснование сделанному утверждению дает анализ звукосмысловых соответствий, существующих в русском языке. Построенная фоносемантическая шкала не апеллирует к конкретным признакам, присущим оценочным фоносемантическим шкалам, а значит, может быть атрибутирована как естественная. Она отображает свойства звуковых форм слов в терминах их структурной неординарности, соотнесенной с понятийными ядрами.
Естественная шкала избегает искусственного противопоставления полюсов-антонимов, обращаясь к оцениванию изначальной звуковой формы слова. Она не связана с антонимической системой противоречий, в большинстве своем основанных на чисто субъективной природе восприятия. Частотные оценки слов имеют иное содержание, основываясь не на близости образа звуковой формы к полюсам, а на соотношении с языковой нормой. Модель однозначно задает такую норму:
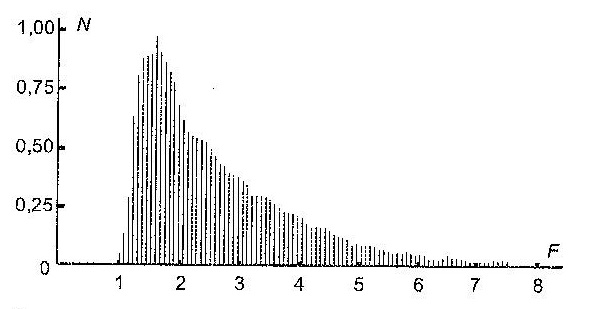
Рис. 4. Вид распределения относительного количества слов по частотной информативности.
Основываясь исключительно на распределении слов по значениям их частотной информативности (рис. 4), можно сделать ряд выводов. Превышение частотной информативностью слова правой границы области нормальной дисперсии свидетельствует о его «неординарном» звучании. Ситуация за левой границей соответствует «ординарности» образа слова, его бесструктурности, отождествлению с единицей языка – звукобуквой.
Описание фонетической (фоносемантической) мотивированности
в частотной модели.
После построения частотной модели структурной неординарности слов и введения частотной информативности, как ее количественной характеристики, появляется реальная возможность количественного способа описания фонетической частотной мотивированности, проявления общей тенденции к мотивированности русского языка.
Не затрагивая количественное обоснование, обратимся к качественной стороне вопроса. Выделим группу слов, содержащих явно выраженный общий признак, то есть лексико-семантическую группу. Очевидно, что мотивированность, то есть связь звуковых форм слов группы и их понятийных ядер (допустим, что она существует), проявляет себя через отличие звуковых форм друг от друга. Противное означало бы полную независимость звуковых форм от смысла слов, то есть произвольность номинации.
Отличия в структурной неординарности слов могут быть зафиксированы через вариации их частотных информативностей на среднем фоне частотной информативности всей группы. Он представляет собой «информационный» шум, который, с одной стороны, значением средней частотной информативности характеризует усредненную структурную неординарность слов группы - с другой стороны, демпфирует, сглаживает, отличия слов внутри группы, так как любое абсолютное отличие воспринимается тем в меньшей степени, чем меньше его относительная величина по сравнению с фоном. Отклонение от уровня среднего фона следует расценивать как проявление частотной мотивированности, которая выражена тем сильнее, чем больше дисперсия частотных информативностей звуковых форм группы.
В качестве количественной оценки частотной мотивированности естественно использовать отношение среднеквадратичного отклонения

мотивированности группы можно ожидать, что М по абсолютной величине окажется близким к единице, характеризуя своим значением предельно допустимую дисперсию звуковых форм в рамках набора.
Примечание: Из-за проблем перевода сложных символов на язык сайта мы отступили от принятых обозначений некоторых понятий в фоносемантике. Срдние частотные информативности в некоторых местах текста обозначили символом «f», а дисперсии – символом «z». Ряд формул пришлось представить в виде фотокопий. Специалисты смогут уточнить неясные места в тексте, ознакомившись с книгой в столичных публичках.
1. Агапьев Б. Д., Белов В. Н., Кесаманлы Ф. П. и др. Обработка
экспериментальных данных. СПб, Нестор, 1999, 84 с. С. 64 - 66.
2. Алешковский М. Х. Повесть временных лет. М., Наука, 1971, 134 с.
3. Большой русско-польский словарь, в 2 т. Москва-Варшава, Русский язык - Везда Повшехна, 1986 - 1987.
4. Василенко И. А. Историческая грамматика русского языка. М.,
Просвещение, 1965, 300 с.
5. Виноградов В. В. История слов. М., изд. РАН, 2000, 1138 с.
6. Военный энциклопедический словарь, в 2 т. М., БРЭ, Рипол - классик, 2001.
7. Воронин С. В. Основы фоносемантики. Л., изд. ЛГУ, 1982, 244 с.
8. Гумилев Л. Н. От Руси до России. М., Рольф, 2001, 320 с.
9. Даль В. И. Толковый словарь. М., ГИХЛ, 1935, в 4 т.
10. Журавлев А. П. Фонетическое значение. Л., изд. ЛГУ, 1974, 160 с.
11. Журавлева Т. С. Содержательность звуков речи в межъязыковом аспекте. //Автореферат дис. …канд. филол. наук. М., 1983, 20 с.
12. История войн и военного искусства. М., Воениздат, 1970, 560 с.
13. Кулешова О. Д. Фонетическая содержательность звуков английского языка.// Фоносемантические исследования. Пенза, 1990, 176 с. С. 120 - 127.
14. Линдер И. М. Шахматы на Руси. М., Наука, 1975, 208 с.
15. Линдер И. М. Мир шахматных фигур. М., АО ХГС, 1994, 288 с.
16. Ожегов С.И. Словарь русского языка. М., Русский язык, 1978, 848 с.
17. Орбели И. А., Тревер К. В. Шатранг. Книга о шахматах. Л., 1936, 196 с.
18. Орфографический словарь русского языка. / Под ред. Бархударова С. Г.,
Протченко И. Ф., Скворцова Л. И. М., Русский язык, 1980, 400 с.
19. Персидско-русский словарь, в 2 т. М., Русский язык, 1985.
20. Петрухин А. Ф. Содержательность звуковой формы поэтического
произведения (на материале немецкой поэзии) // Автореферат дис.
канд. филол. наук. М., 1978, 26 с.
21. Русско-персидский словарь. М., Русский язык, 1986, 832 с.
22. Советский энциклопедический словарь. М., СЭ, 1980, 1560 с.
23. Словарь древнерусского языка АН СССР 11 - 14 вв., в 10 т. / Под ред.
Аванесова Р. И., М., Русский язык, 1988.
24. Словарь русского языка XI – XVII вв. М., Наука, 1975 – 1999 ( А – С).
25. Срезневский И. И. Словарь древнерусского языка, в 3 т. М., Книга, 1989.
26. Тынянов Ю. Н. Проблема стихотворного языка. М., Сов. писатель, 1965,301 с.
27. Улуханов И. С. О языке Древней Руси. М., Наука, 1972, 135 с.
28. Шахматы. Энциклопедический словарь. М., СЭ, 1990, 622 с.
29. Якубинский Л. П. История древнерусского языка. М., Учпедгиз, 1953, 36 с.
Конец
|
|